
最近几天,DeepSeek V4 发布,也引了不小的轰动,这次发布包含了两个模型,分别是
一、上下文升级:128K tokens → 1M tokens
这也许是 DeepSeek V4 对比 V3 最大的升级了,128K tokens 已经很强了,差不多相当于几十万字的文档,1M tokens 是什么概念呢,相当于你把一整本《三体》的三部曲丢给他,他甚至都能分析出来,这就逆天,更逆天的是,就连DeepSeek V4-flash 都有 1M 超长上下文,这意味着,你可以只花传统大模型十分之一的成本,就可以获得超长上下文和超快速响应。
这对大仓库的开发者也十分友好,你可以直接把一整个仓库丢给它,让他给你修藏了特别深的 Bug,且成本极低。
二、推理能力超强
DeepSeek V3(R1)版本的推理能力已经很强了,但这次 V4 版本又进行了全面升级,主要升级在编程、数学和 Agent 能力上,而且这次也首次引入了思考强度设置,提供了 High 和 Max 两个选项,尤其在 Max 下表现优异:
(1) 默认思考开关为 enabled
(2) 思考模式下,对普通请求,默认 effort 为 high;对一些复杂 Agent 请求(如 Claude Code、OpenCode),effort 自动设置为 max
(3) 思考模式下,出于兼容考虑 low、medium 会映射为 high, xhigh 会映射为 max
可以通过 OpenAI API 在请求时传参实现思考:
response = client.chat.completions.create(
model="deepseek-v4-pro",
# ...
reasoning_effort="high", //思考强度
extra_body={"thinking": {"type": "enabled"}} //开启思考
)三、超强多语言支持
DeepSeek V3 基本是中英双语,DeepSeek V4 直接把支持语言拉到了 100+。对于做国际化的项目来说,这绝对是福音。而且据说在多语言混合的场景下表现尤其好——就是你一段话里夹三种语言那种,它也能精准理解。
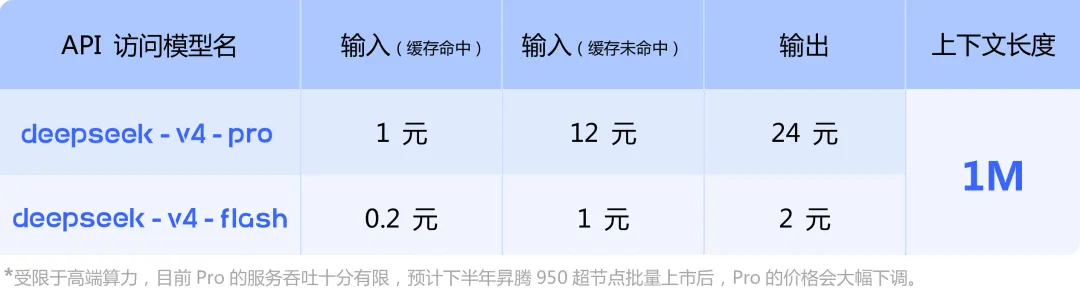
四、价格????
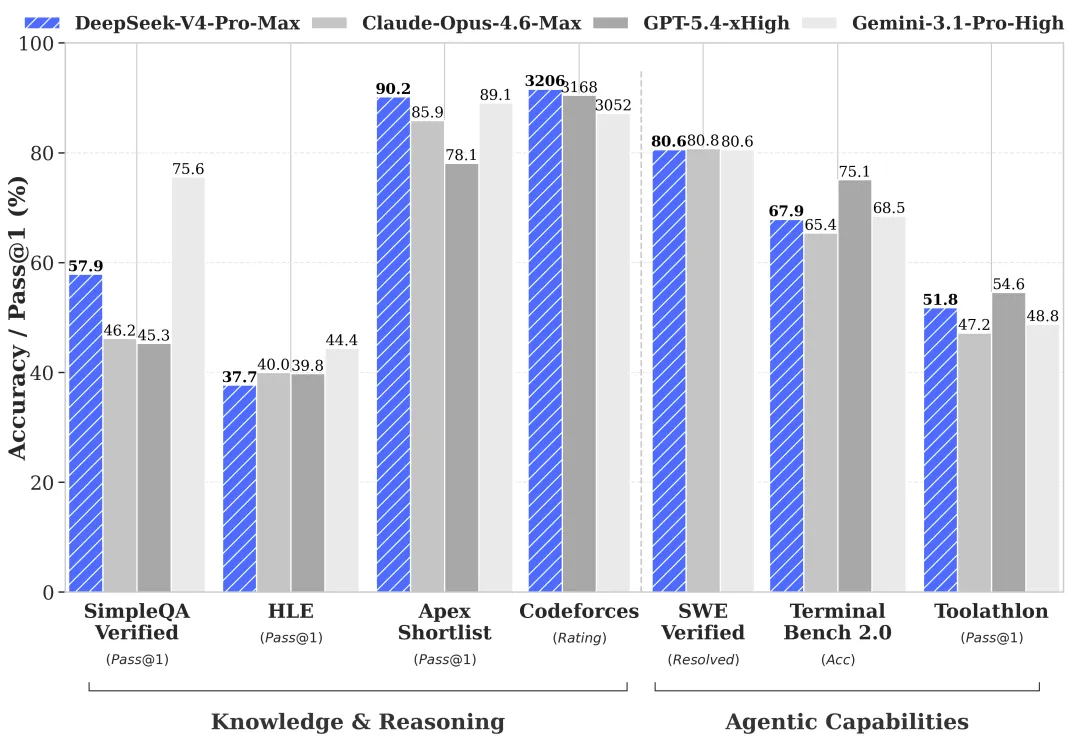
这性能,这价格还要啥自行车:
最后,网上也有流传说是蒸馏的 ChatGPT,但我想说的是 清者自清,毕竟太敏感了,我还不想网站被封。
默认评论
Halo系统提供的评论